Deep Reinforcement Learning for Autonomous Vehicles
Application of Deep Reinforcement Learning algorithms to train autonomous driving agents in complex simulated environments using the MetaDrive simulator.
github.com/pompos02/MetaDriveRLagentOverview
This project explores the use of Deep Reinforcement Learning (DRL) techniques to develop intelligent autonomous driving agents capable of navigating various road geometries and traffic conditions. The implementation compares different training approaches, from Stable Baselines3 to custom PyTorch implementations, and investigates both sensor-based (Lidar) and vision-based (RGB camera) observations.
MetaDrive is an advanced open-source simulation environment specifically designed for developing and evaluating autonomous driving models. Built on technologies like Panda3D and OpenAI Gym, it enables the creation of realistic and customizable driving environments.
Technical Stack
- DRL Framework: Stable Baselines3, PyTorch
- Simulation Environment: MetaDrive (built on Panda3D and OpenAI Gym)
- Algorithm: Proximal Policy Optimization (PPO)
- Python Version: 3.10
Initial Implementation - Straight Road
The agent's training was initially conducted in a simple geometry environment—specifically an empty straight road—to familiarize it with basic driving principles. A custom environment class was created that inherits from MetaDrive's default environment with specialized parameters.
Sensors Configuration:
- Lidar: 72 points
- Side detector: 20 points
- Lane line detector: 20 points
Policy Network Architecture:
- 2 hidden layers with 256 neurons each
- ReLU activation function
- Training steps: 2,000,000
Training Parameters:
- Steps per update: 4096
- Batch size: 256
- Learning rate: 1e-4
- Gamma: 0.99
- Entropy coefficient: 0.1 (enhanced exploration)
Initial Results:
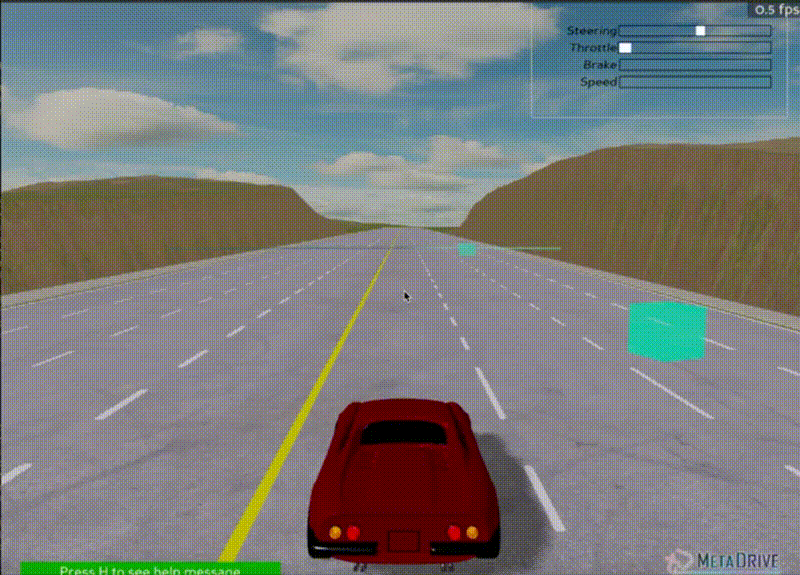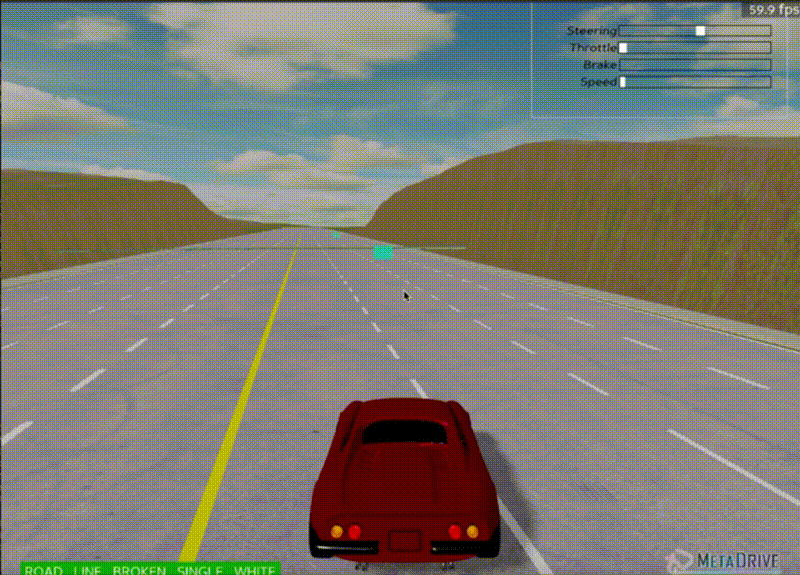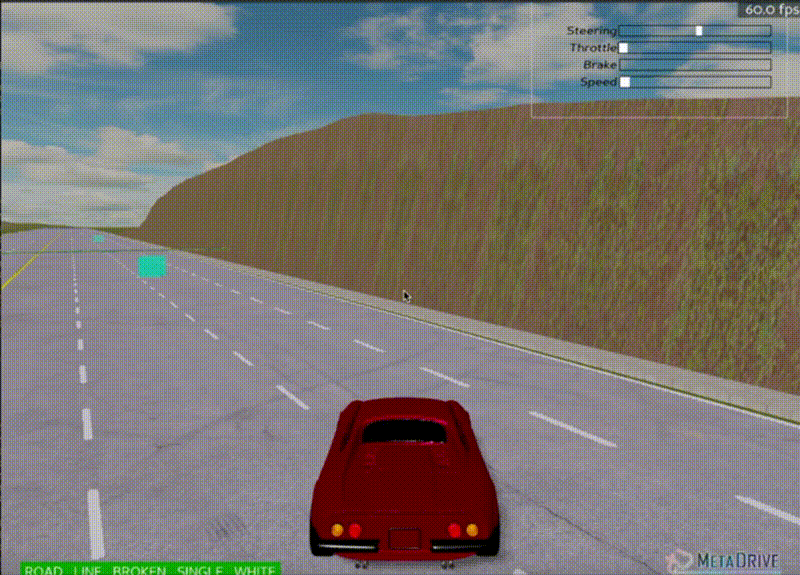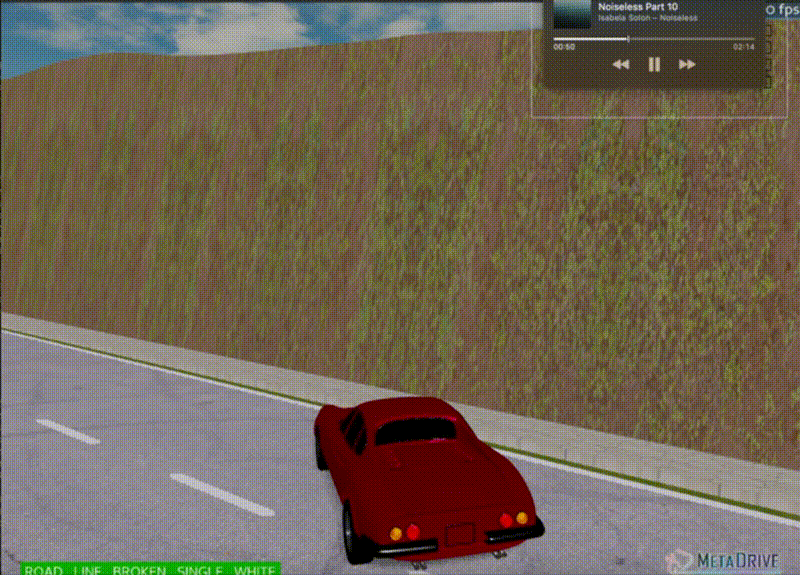
Agent at 10,000 steps - Learning basic movement
Agent at 2,000,000 steps - Exhibiting "slalom" behavior
Initial results showed the agent learned to move toward the goal but exhibited non-smooth behavior, performing "slalom" type maneuvers.
Improved Reward Function
To improve driving stability, the reward function was redesigned to include checking the vehicle's position relative to the reference lane and calculating the distance traveled between consecutive steps.
Original Speed Reward:
R_speed = SpeedReward × (vehicle.speed / vehicle.max_speed)Added Driving Reward:
R_driving = d × StepDistance × positiveRoadWhere d is a reward weight coefficient and positiveRoad indicates whether the vehicle is moving on the correct side of the road.
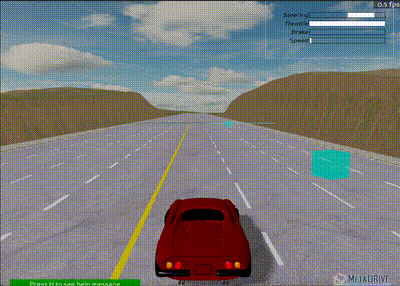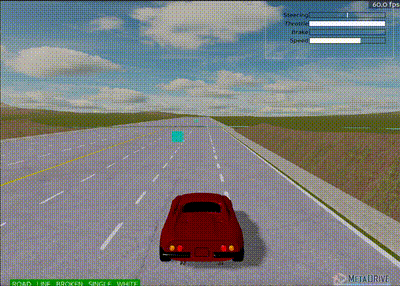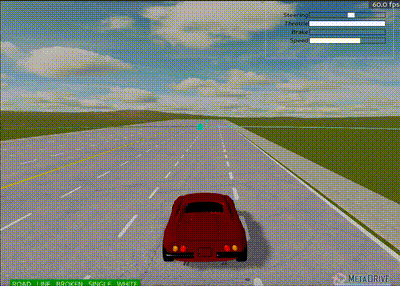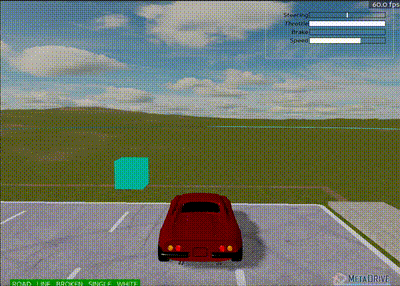
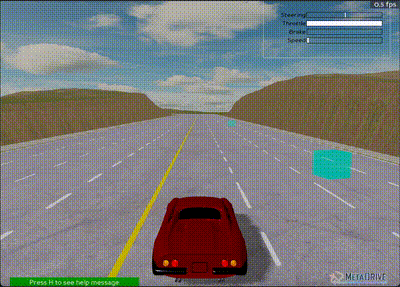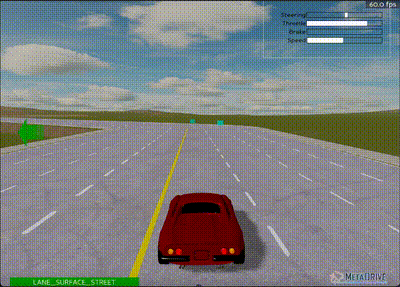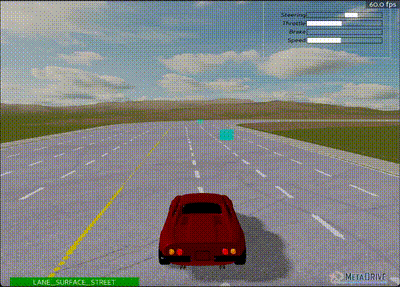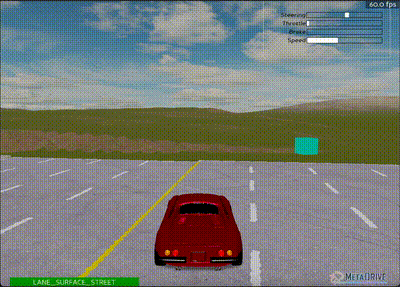
Updated agent after 3,000,000 steps - Smoother driving behavior achieved
Adding Turns
The road geography was changed by adding two turns. Training revealed an interesting challenge: during training, the average reward was approximately 700 (indicating completion), but in deterministic evaluation, the car repeatedly crashed at the first turn.
Challenge Identified:
- Training speed: ~30 km/h (stochastic policy with exploration)
- Evaluation speed: ~80 km/h (deterministic policy)
- PPO's stochastic nature causes continuous micro-corrections limiting speed
Solution:
Reduced the standard deviation (stochasticity) of the policy during training to minimize the training-evaluation gap, making the model behave more similarly in both phases.
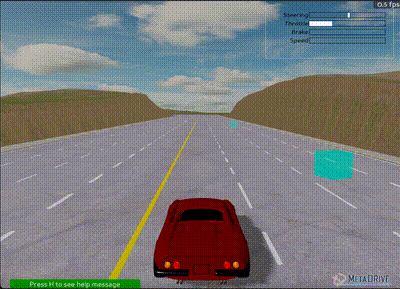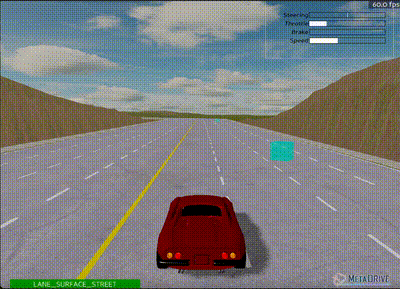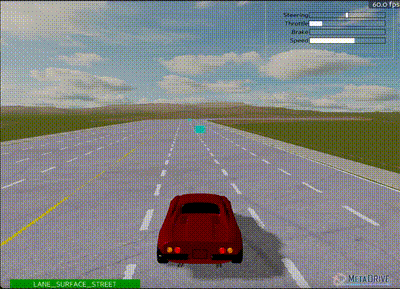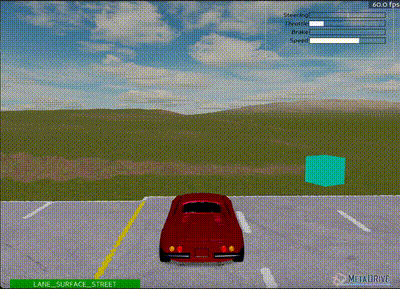
Agent successfully navigating turns after adjustments

Training metrics showing improvement over time
Custom PyTorch Implementation
To gain a better understanding of how the PPO agent works "under the hood," the learning logic was rewritten exclusively with PyTorch. This provided better control over the training process with more low-level knowledge of the algorithm.
Architecture Components:
- Actor-Critic Network: MLP combining an actor (generates actions) and critic (estimates state values)
- Rollout Buffer: Stores agent experiences during training
- PPO Update Function: Implements clipped surrogate objective, value function loss, and entropy bonus
- Main Training Program: Coordinates overall training process
Separated Actor-Critic Architecture:
- Complete separation of Actor and Critic networks
- MultivariateNormal distribution for action modeling
- Multiple episodes collection for each update
- Simplified advantage calculation
Challenges Encountered:
Results were considerably worse compared to the Baseline3 implementation, likely due to "unstable" training. This was evident from significant fluctuations in all graphs (even with smoothing), which was unexpected since the environment is relatively deterministic.
Custom PyTorch implementation after 3,000,000 steps - Less stable than Baseline3
Key Finding:
Despite extensive experimentation with different hyperparameters and architectures, the custom implementation could not match Baseline3's stability and performance, revealing the importance of implementation details in DRL.
Complex Track with Traffic
An agent was trained to navigate a complex multi-turn track, initially without traffic, then with traffic added for realism. Due to the complexity, a comprehensive multi-component reward function was designed.
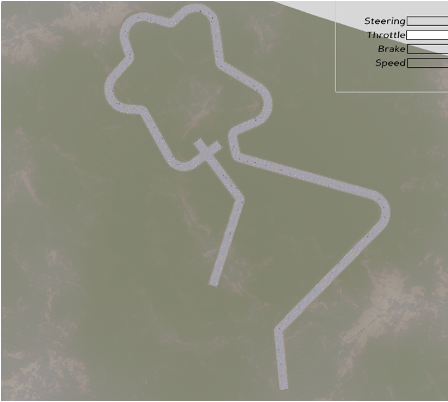
Complex multi-turn track layout used for advanced training
Comprehensive Reward Function Components:
- Speed Control: R₁ = c₁ × (1 - |v - v_target|/v_target) with penalty for exceeding target speed
- Route Progress: R₂ = c₂ × (L_now - L_last) × roadsign
- Lane Center Deviation Penalty: R₃ = -c₃ × |lat|/w
- Direction Angular Deviation Penalty: R₄ = -c₄ × |θ_diff|
- Smooth Driving: R₅ = -c₅ × (|Δ_steering| + |Δ_throttle|)
- Success Reward: R₆ = +c₆ for reaching destination
- Out-of-Road Penalty: R₇ = -c₇
- Collision Penalty: R₈ = -c₈ (doesn't terminate simulation)
- Time Penalty: R₉ = -c₉ per step
Training Without Traffic (Conservative Approach):
The agent maintained the first lane and moved at 40 km/h when all reward components were active.
Conservative approach - maintaining lane at 40 km/h
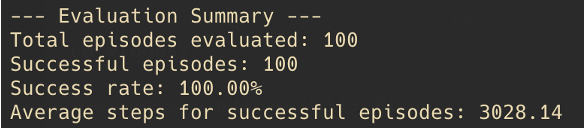
Training metrics for conservative approach
Training Without Traffic (Aggressive Approach):
By removing R₁ (speed control) and R₃ (lane center deviation), the agent moved more freely and completed the track much faster.
Aggressive approach - faster but riskier driving
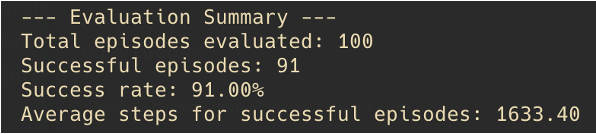
Lower success rate but faster completion times
Adding Traffic:
Adding traffic to the simulation dramatically reduced training speed (from 1000 it/s to 60 it/s). The pre-trained model was retrained with traffic for 5,000,000 steps with v_target = 75 km/h, keeping all reward components except R₃ for potential overtaking capability.
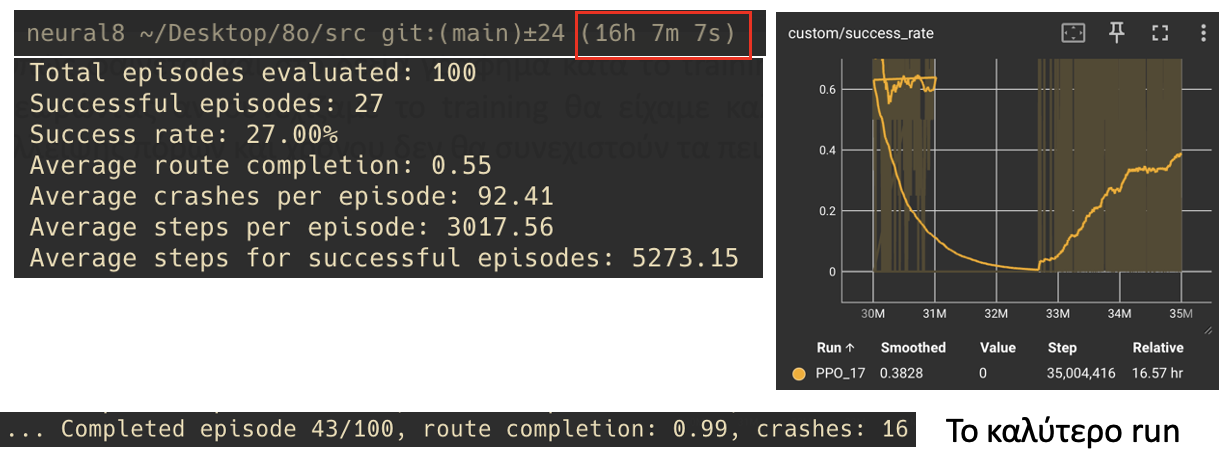
Training metrics showing upward trend in success rate with traffic
Note: The success rate showed an upward trend during training, suggesting that continuing training would yield better results. Unfortunately, due to lack of resources and time, experiments in this environment were not continued.
RGB Camera Input
In this section, the observation sensor was changed to an RGB camera (along with vehicle states) which returns consecutive images. The implementation used PyTorch with a custom CNN-based architecture.
Model Architecture:
- CNN for Visual Processing: Accepts 9-channel inputs (3 consecutive RGB frames)
- Feature Extraction: Three convolutional layers
- Fully Connected Layers: Combining visual features with vehicle state information
- Separate Heads: Actor produces action distributions, Critic estimates state values
Challenges:
- Significantly more computationally demanding than Lidar input
- Much slower convergence
- Initial run on complex track achieved only 14% average progress (after first turn) at 3,000,000 steps
Results on Simplified Track:
Due to time constraints, training was repeated on a simpler track with just 3 turns, showing the camera-based approach's potential but also its computational demands.
Final results showing RGB camera input and agent behavior on simplified 3-turn track
Implementation Challenges
- Apple Silicon Compatibility: Parallelism limitations with SubprocVecEnv and DummyVecEnv
- Deterministic Environments: Used seeded maps to prevent overfitting, though randomized maps would be ideal with more resources
- Computational Resources: Limited ability to train extensively on complex scenarios with traffic
- Training Instability: Custom PyTorch implementation showed significant fluctuations compared to Stable Baselines3
Key Findings
1. Framework Comparison
Stable Baselines3 provided significantly more stable training compared to custom PyTorch implementation, with clear differences in convergence and overall performance.
2. Reward Design
Critical importance of reward function design - incorporating smoothness and progress dramatically improved behavior. Different reward configurations led to conservative vs. aggressive driving styles.
3. Training vs Evaluation Gap
Stochastic policy during training led to different speeds compared to deterministic evaluation, requiring careful tuning of policy standard deviation.
4. Complexity Impact
Adding traffic and complex tracks dramatically increased computational requirements (1000 it/s → 60 it/s).
5. Sensor Choice
RGB camera input proved much more demanding than Lidar-based observations, both computationally and in terms of convergence speed.
Conclusions
The research revealed that the Stable Baselines3 architecture offers significantly more stable training compared to custom PyTorch implementations, with clear differences in convergence and overall performance. The design of the reward function played a critical role, where incorporating parameters such as driving smoothness and route progress significantly improved vehicle behavior.
A significant difference was observed between training and evaluation phases, with the vehicle developing higher speeds during evaluation due to the non-stochastic nature of decisions. Adding traffic and complexity to the track dramatically increased computational requirements, while using an RGB camera as input proved significantly more demanding both computationally and in terms of convergence.
The work demonstrates the need for careful balance between environment complexity, reward function design, and computational resources for successful training of autonomous vehicles using deep reinforcement learning techniques.