Greek Parliament Information Retrieval
A comprehensive system for analyzing and extracting insights from speeches in the Greek Parliament spanning 1989–2024, featuring full-text search, topic modeling, clustering, and sentiment analysis.
github.com/pompos02/Greek_Parliament_Information_Retrieval_1989_2024Video demonstration of the web applicationOverview
This project creates a robust system for analyzing parliamentary discourse over 35 years of Greek political history. By processing and structuring thousands of speeches, the system enables researchers, journalists, and citizens to explore political trends, track key topics, identify ideological alignments, and understand how political sentiment has evolved over time.
Technical Stack
- Database: PostgreSQL
- NLP Processing: SpaCy (el_core_news_sm), NLTK for Greek text analysis
- Machine Learning: scikit-learn for TF-IDF, LSI, NMF, K-Means clustering
- Web Application: Interactive interface for search and visualization
- Data Processing: Python, pandas for data manipulation
Core Features
1. Data Retrieval and Management
- Automated retrieval of raw speech data from parliamentary records
- Structured storage in PostgreSQL database with two tables:
speeches: Individual speech recordsmerged_speeches: Consolidated speeches per MP per sitting- Preprocessing pipeline for efficient querying and analysis
2. Full-Text Search Engine
- Advanced querying capabilities with TF-IDF-based similarity ranking
- Cosine similarity for relevance scoring of search results
- Paginated interface displaying MP names, speech summaries, and full text
- Accessible via the /search_engine route
Search engine interface before query
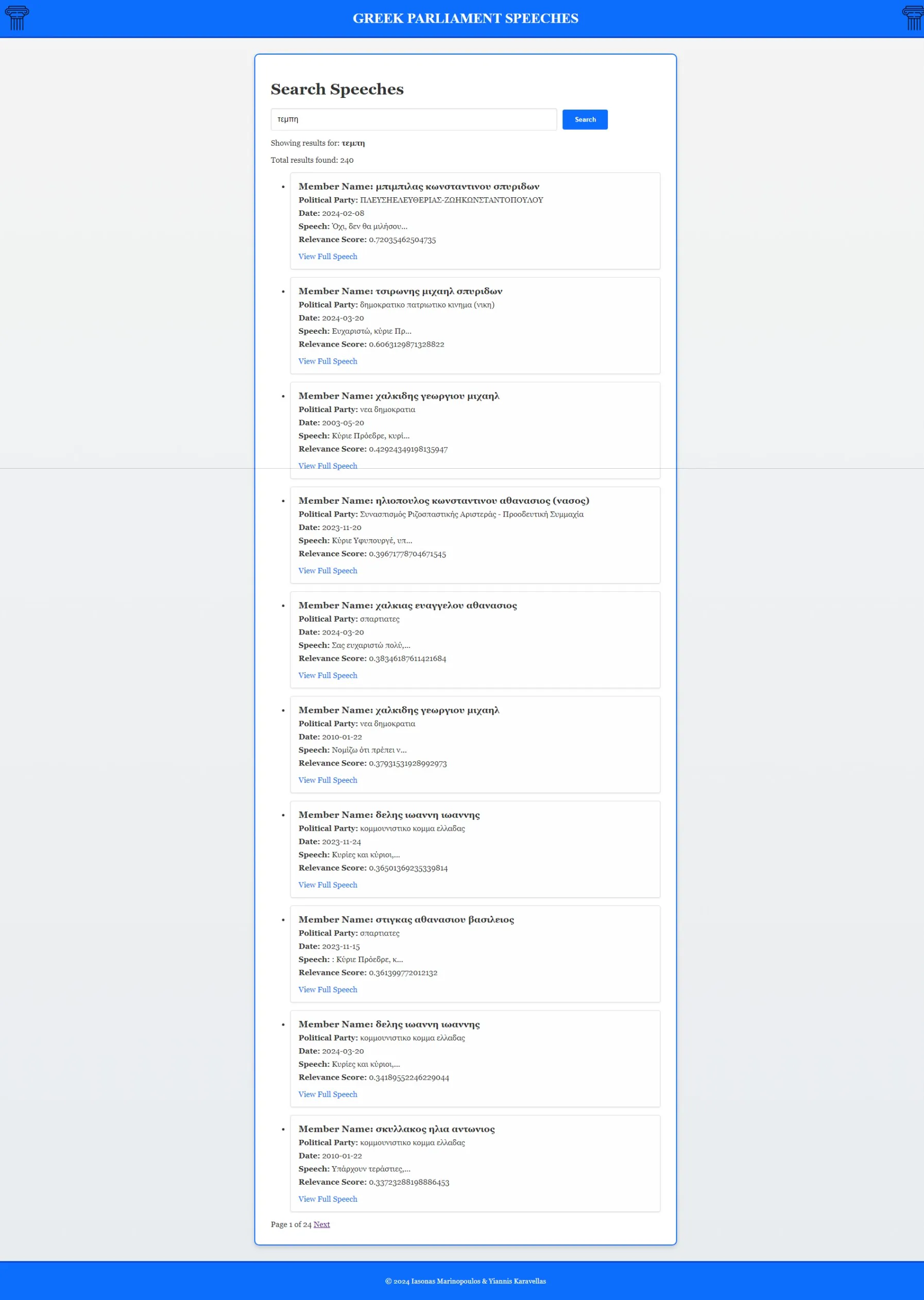
Search results ranked by relevance

Full speech view with detailed information
3. Keyword and Similarity Analysis
- Top-K keyword extraction at multiple granularities:
- Individual speeches
- Members of Parliament (MPs)
- Political parties
- Temporal analysis tracking keyword evolution over time
- MP similarity scoring using cosine similarity on TF-IDF vectors
- Top-K pairs identification revealing ideological alignments
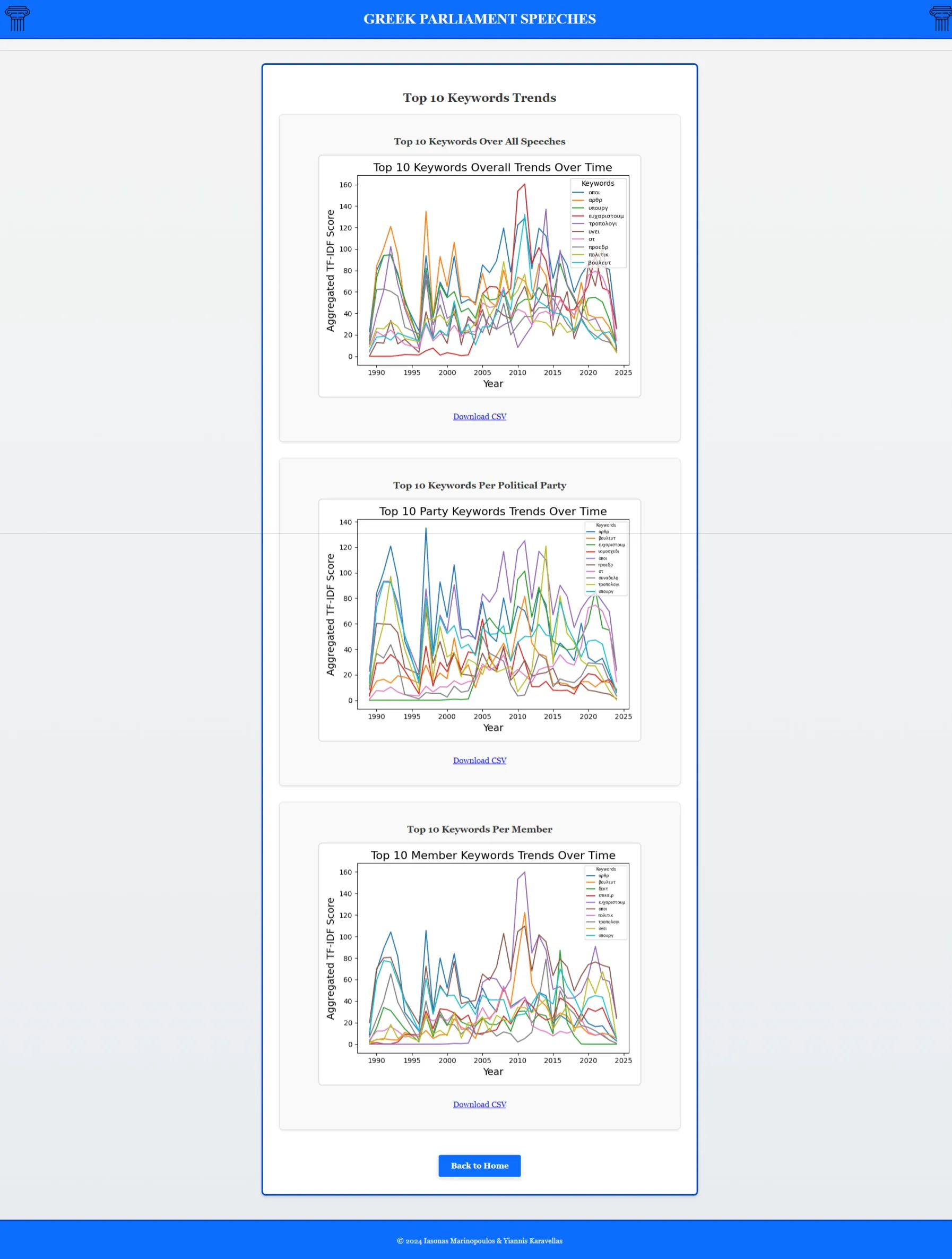
Interactive interface for tracking keyword trends over time
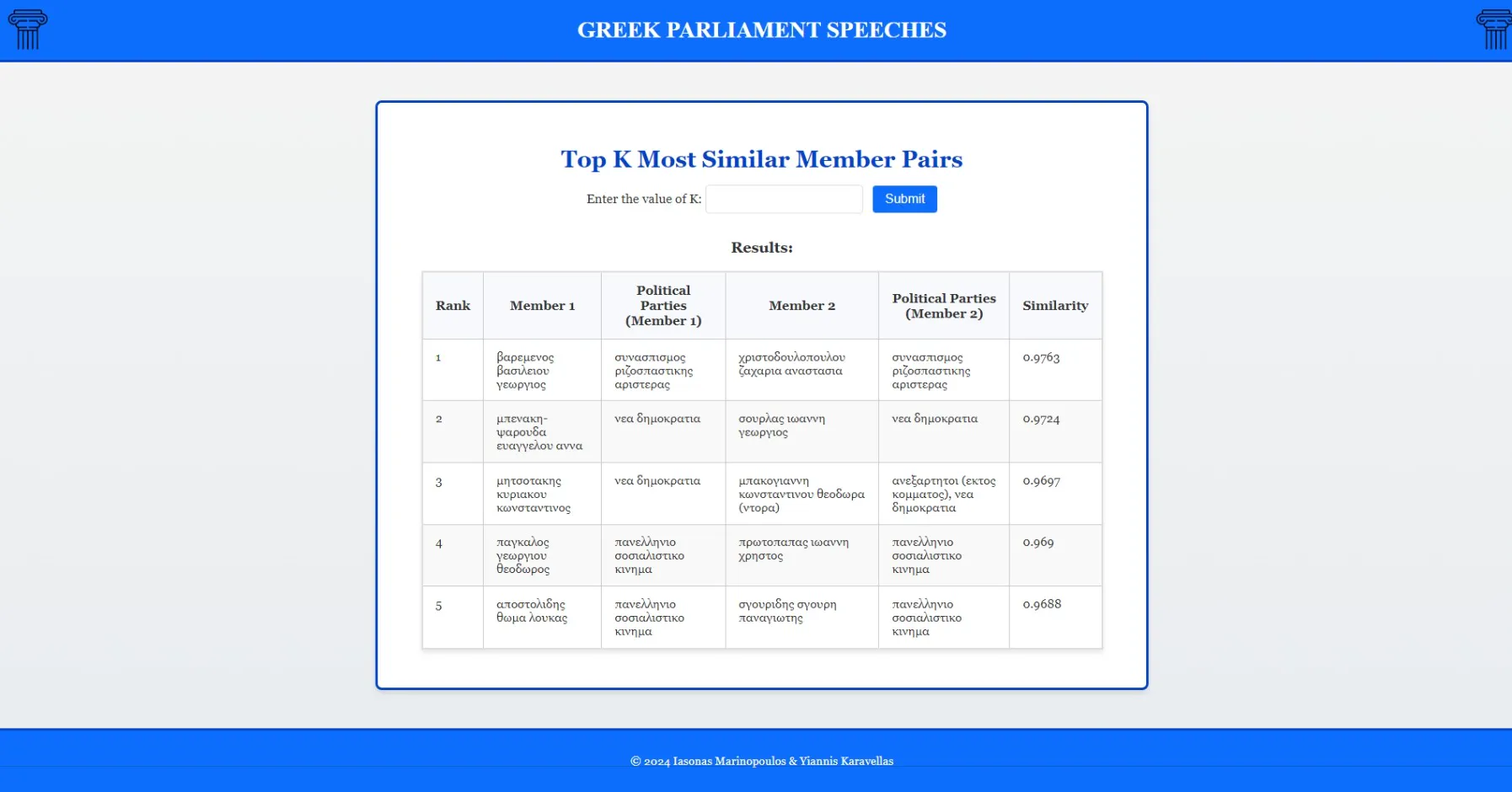
Top 5 MP pairs by similarity score
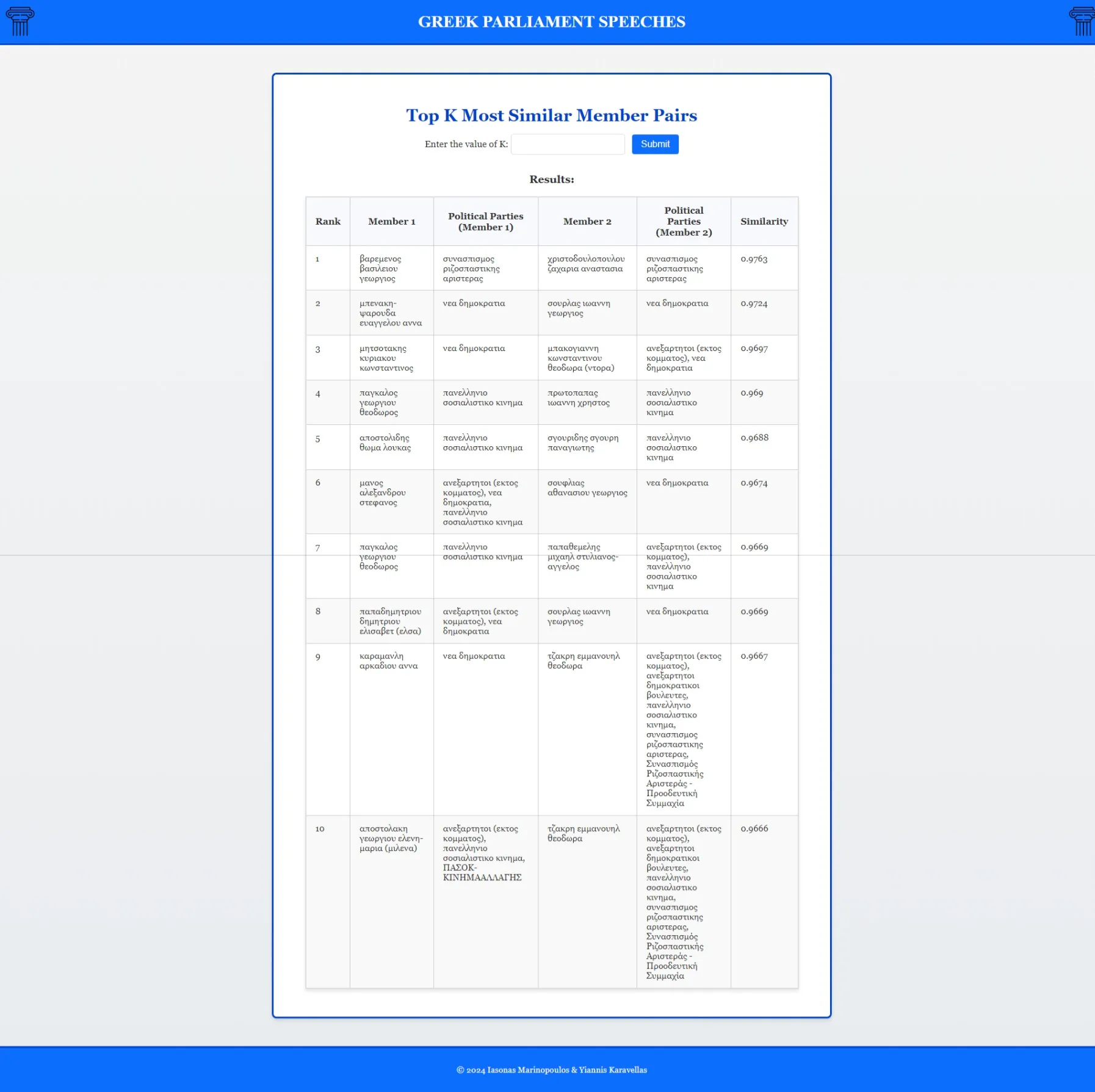
Top 10 MP pairs revealing ideological alignments
4. Topic Modeling
- Latent Semantic Indexing (LSI) for thematic area identification
- Dimensionality reduction of TF-IDF matrix to reveal latent concepts
- Key terms extracted per concept with interpretable themes
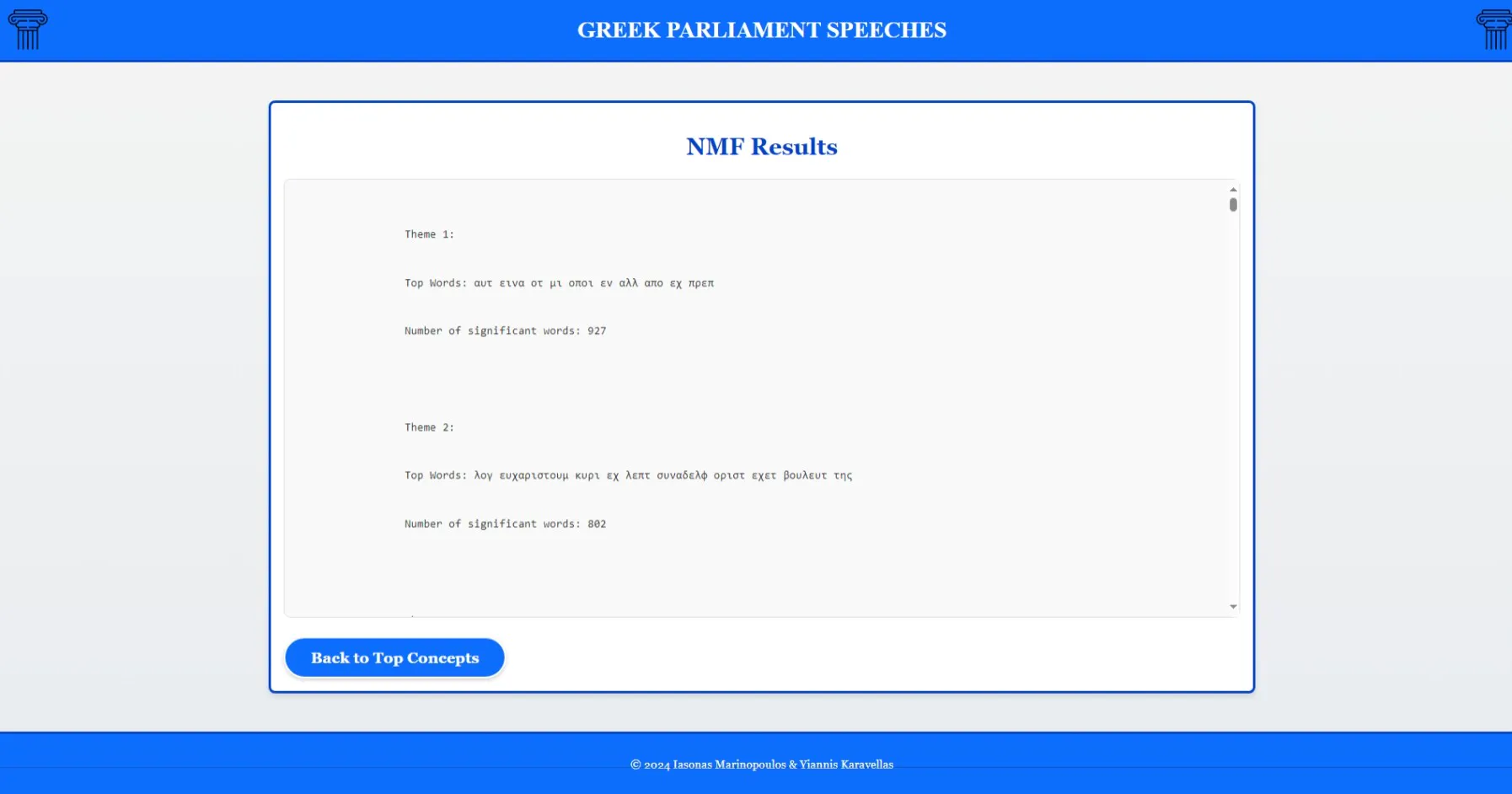
- Alternative approach using Non-Negative Matrix Factorization (NMF)
- Reduced-dimensional representation for visualization and clustering
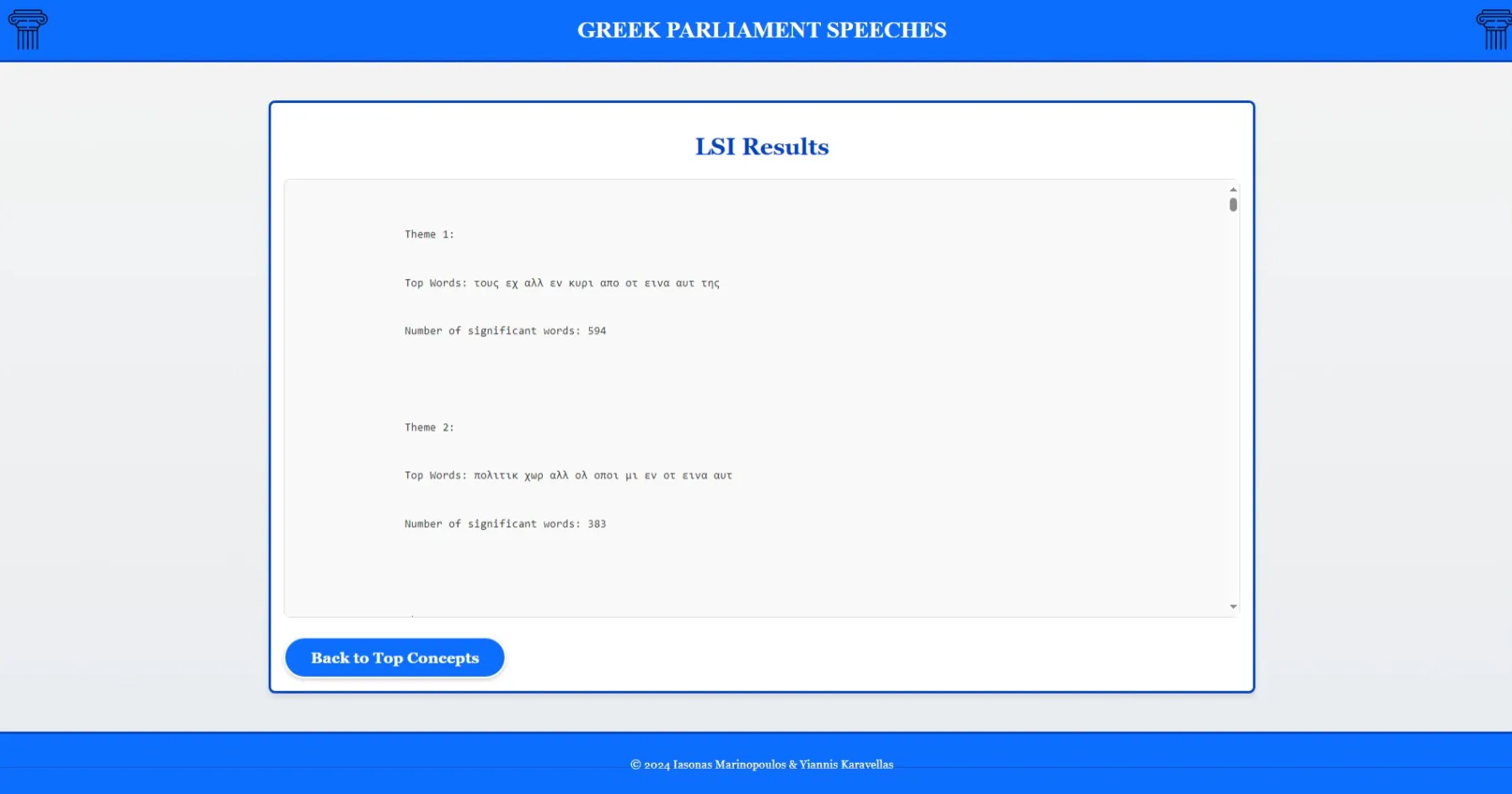
LSI-identified thematic concepts with key terms
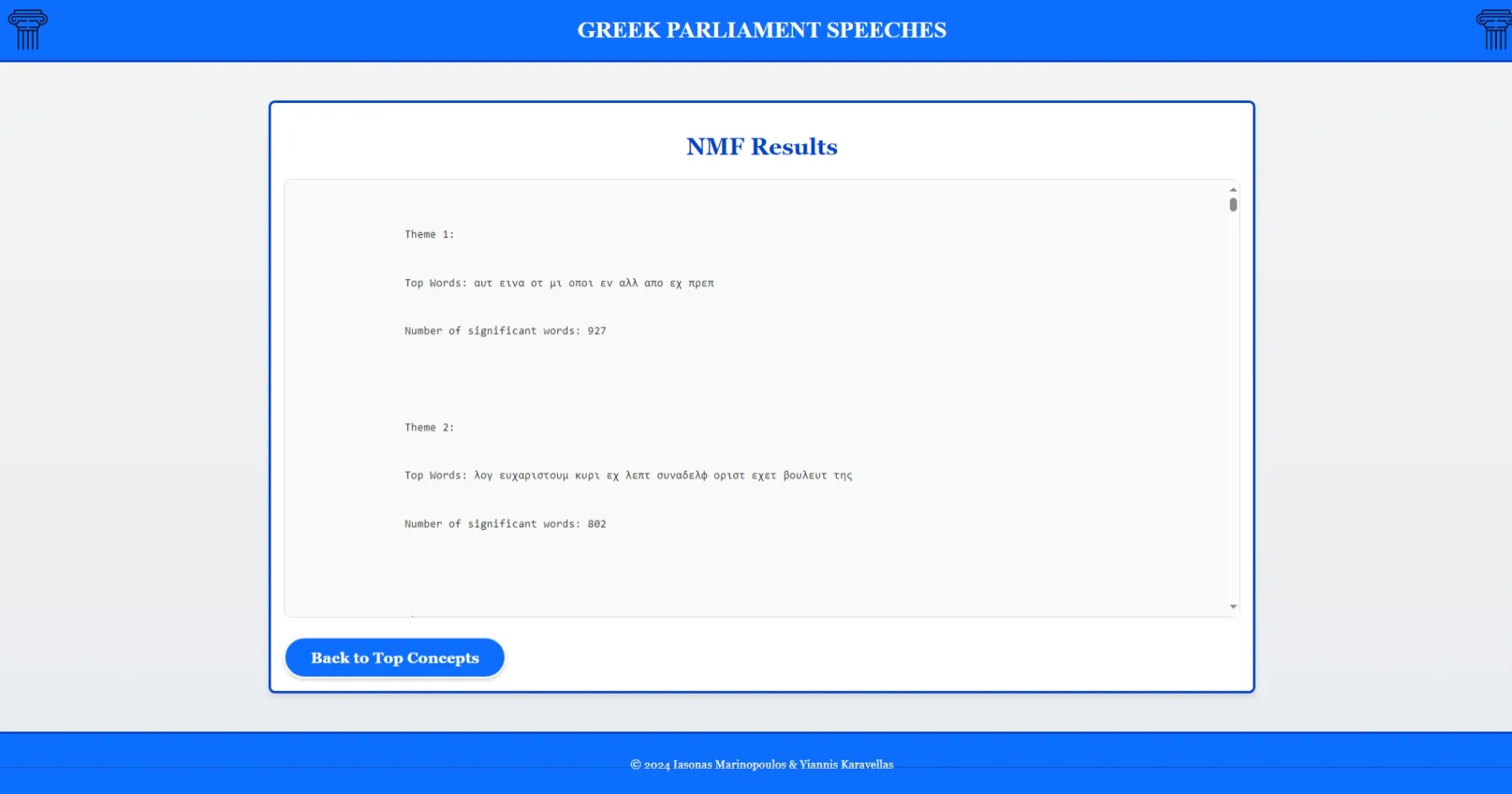
NMF-identified topics for comparison
5. Speech Clustering
- K-Means clustering applied to LSI-reduced speech vectors
- Automatic grouping of speeches into thematic clusters
- Pattern discovery revealing divisions in political discourse
- Comparative evaluation of LSI vs. NMF for clustering performance
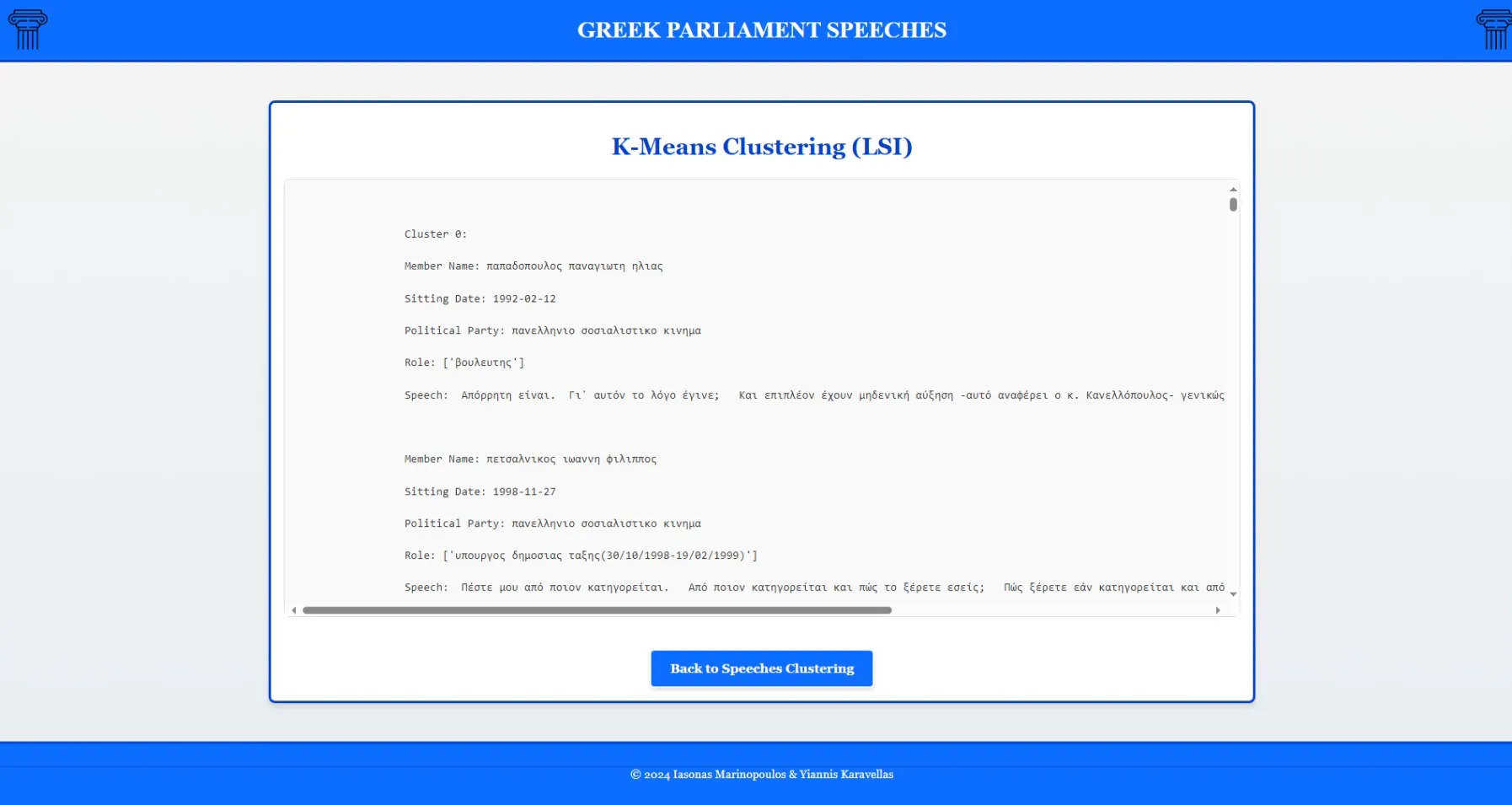
K-Means clustering results using LSI features
K-Means clustering results using NMF features
6. Sentiment Analysis
- Polarity scoring for political party speeches over time
- Temporal tracking of sentiment evolution across parties
- Identification of most positive and negative keywords per political group
- Frequency analysis of sentiment-bearing terms with visualization
- Insights into rhetorical strategies and political positioning
Sentiment polarity tracking by parliament group over time
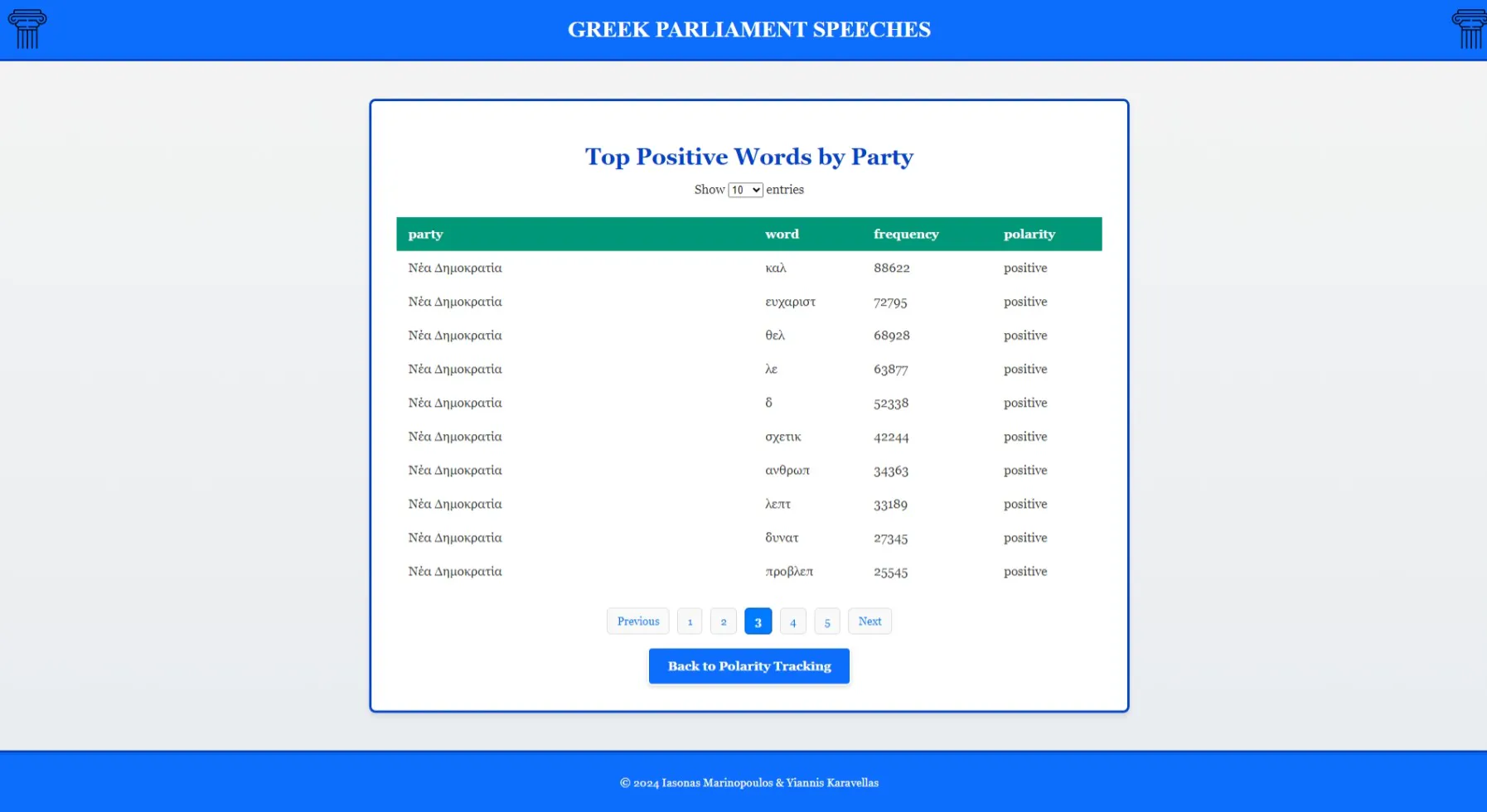
Most positive keywords per political group
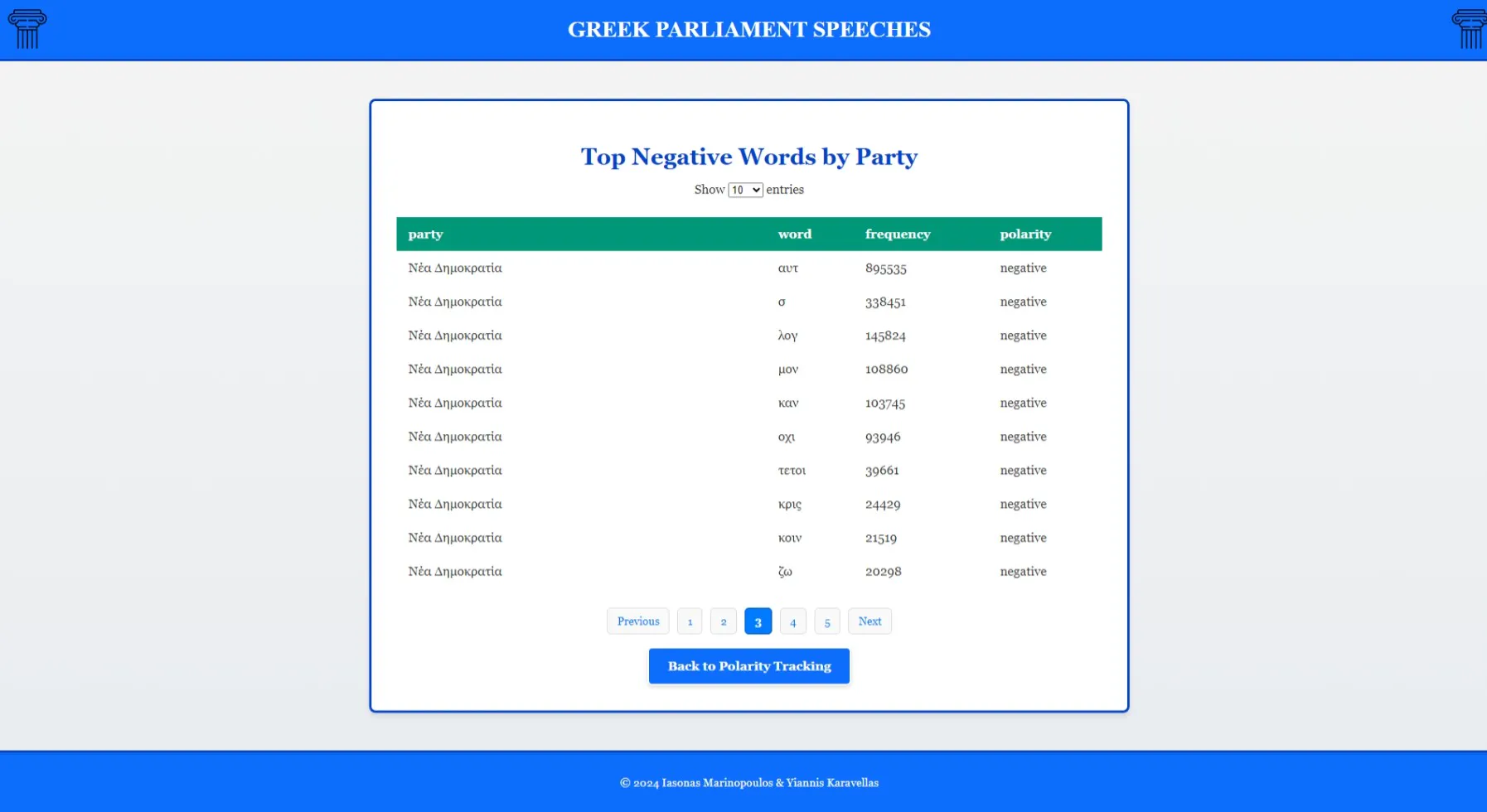
Most negative keywords per political group
Implementation Details
Data Processing Pipeline
- Greek language processing using specialized SpaCy model (el_core_news_sm)
- NLTK integration for additional Greek text preprocessing
- Speech merging logic consolidating MP contributions per sitting
- Efficient indexing for rapid search and retrieval
Machine Learning Pipeline
- TF-IDF vectorization capturing term importance across speeches
- LSI dimensionality reduction revealing latent semantic structures
- K-Means clustering for unsupervised thematic grouping
- Cosine similarity metrics for MP alignment analysis